
Googleスプレッドシートは、Googleの提供しているオンライン表計算アプリです。
無料で使えて、Webブラウザ上で動作するので、Googleアカウントがあれば端末や場所を問わず、どこからでも使用できます。
Microsoft Excelと違い、Google独自の関数やWeb系の関数があって、これがなかなか便利です。
今回は、その中のIMPORTHTML・IMPORTXML関数を使用して、スクレイピング(Webサイトから情報を抽出)をしてみます。
IMPORTHTML・IMPORTXML関数の詳細
IMPORTHTML・IMPORTXML関数は、関数一覧を見るとともにウェブの関数に分類されています。

関数の概要は、以下の通りです。
- IMPORTHTML … HTMLページ内の表やリストからデータをインポート。
- IMPORTXML … XML、HTML、CSV、TSV、RSSフィード、ATOM XMLフィードなど、さまざまな種類の構造化データからデータをインポート。
関数の構文は、次のようになっています。
=IMPORTHTML(URL, クエリ, 指数) クエリ … "list"(リスト)/ "table"(表) 指数 … HTMLページ内で出現する順番に1から連番
=IMPORTXML(URL, XPathクエリ)
IMPORTHTML関数は、リスト(liタグ)かテーブル(tableタグ)のデータをそのままの形で取得できます。
取得は簡単ですが、複雑なことはできない模様。
IMPORTXML関数は、XPathを使用してHTMLページ内の任意の項目のデータを取得できます。
また、HTML以外の構造化データからも取得できます。
複雑なことができますが、XPathを理解する必要があります。
IMPORTHTML・IMPORTXML関数でスクレイピング
では、実際にIMPORTHTML・IMPORTXML関数を使ってスクレイピングします。
取得するデータは、当ブログトップページのサイドバーに表示しているカテゴリー一覧のリストです。
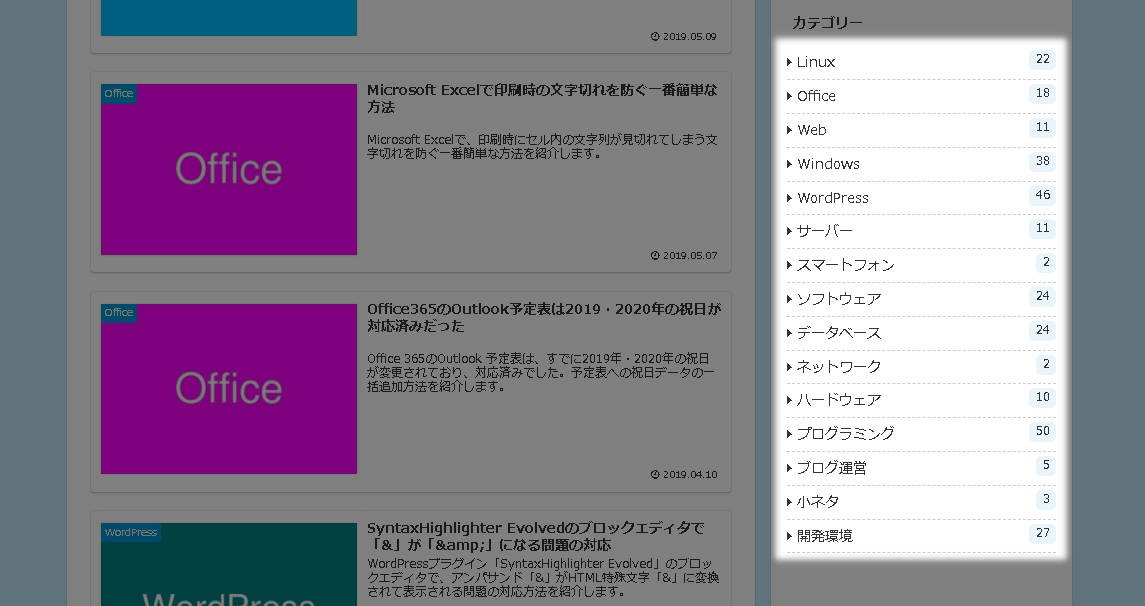
Chromeで確認したところ、該当箇所のHTMLソースはこのようになっていました。
<aside id="categories-2" class="widget widget-sidebar widget-sidebar-standard widget_categories">
<h3 class="widget-sidebar-title widget-title">カテゴリー</h3>
<ul>
<li class="cat-item cat-item-149">
<a class="cf" href="https://itlogs.net/category/linux/">
Linux<span class="post-count">22</span>
</a>
</li>
<li class="cat-item cat-item-338">
<a class="cf" href="https://itlogs.net/category/office/">
Office<span class="post-count">18</span>
</a>
</li>
…
</ul>
</aside>
先に取得結果と式を載せると、次のような感じです。
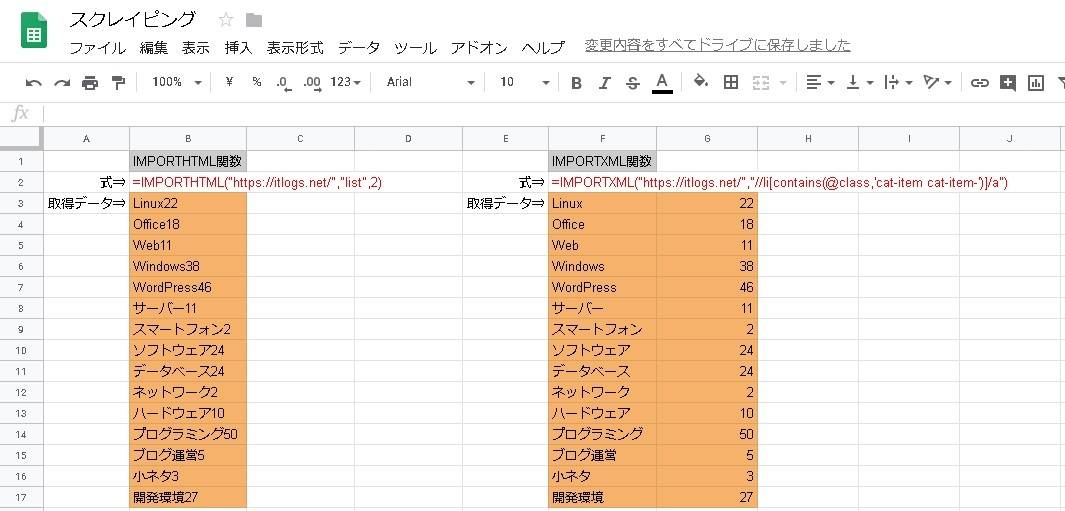
左側がIMPORTHTML関数で取得したもの、右側がIMPORTXML関数で取得したものです。
IMPORTHTML関数でテーブル・リストを簡単スクレイピング
まずは、IMPORTHTML関数から。
こちらは簡単で、取得したいデータはリスト、出現位置はヘッダーメニューの次で2番目なので、以下の式で取得できます。
=IMPORTHTML("https://itlogs.net/","list",2)
ただし、カテゴリー名の後ろについている投稿数も同じリストの値に含まれており、くっついて一緒に取得されています。
これは置換とかで消す対応しかないかなぁ。
IMPORTXML関数はXPathで任意のデータを取得可能
続いて、IMPORTXML関数。
こちらはXPathで項目を指定するので、該当箇所のリストを特定できるようにclass属性に「cat-item cat-item-」が含まれるものを指定しています。
投稿数はspanタグで囲われていますが、上位のaタグを指定することで、いい感じに2列で表示してくれます。
=IMPORTXML("https://itlogs.net/","//li[contains(@class,'cat-item cat-item-')]/a")
また、以下の2つの式でカテゴリー名と投稿数を別々に取得することもできます。
=IMPORTXML("https://itlogs.net/","//li[contains(@class,'cat-item cat-item-')]/a/text()")
=IMPORTXML("https://itlogs.net/","//li[contains(@class,'cat-item cat-item-')]/a/span")
XPathは上位のasideタグにid属性が付いているから、
"//aside[@id='categories-2']/ul/li/a"
でも取得できるかなと思ったのですが、どう頑張っても「インポートしたコンテンツは空です。」となって無理だったので諦めました。
表示されているHTMLソースでは合っていると思うんですが、XPathが長く複雑になると取れない…?WordPressの動的サイトだから…?よく分かりません。。
IMPORTHTML・IMPORTXML関数の注意点
IMPORTHTML・IMPORTXML関数を使用するにあたっての注意点は、
- データ取得されるタイミングがイマイチ明確ではない。
- XPathは正しくてもデータを取得できない場合がある。
- 多用すると遅い。データ取得できない場合もある。
- すでに値が入っているセルは上書きされないのでエラーになる。
といったことが挙げられます。
ファイルを開いたり、式を変更したりしたタイミングでは、データ取得されるみたいですが、その他のタイミングがイマイチ分からず、たまに気づけばエラー「#N/A」になっているときがあります。
また、上述の通りですが、正しいXPathでもデータ取得できない場合があります。おそらく取得したい項目から指定して短くするのがポイントかな。
そして、多用するとかなり遅くなります。そのせいかデータ取得エラーになる場合もあります。
最後は、複数列・複数行のデータを取得して表示する場合は、その範囲のセルに値が入っていればエラーになるので注意です。
最後に
今回は、GoogleスプレッドシートのIMPORTHTML・IMPORTXML関数を使用して、スクレイピングしてみました。
ノンプログラミングで手軽にスクレイピングができるので、とても便利ですよ。
以上です。
コメント